
Introduction
As we all know, almost every other click on the internet may end up in an "Error 404: Page Not Found" page or error. "Whoops, the page you're looking for does not exist," "Sorry, the requested URL was not found on this server," "Oops, something went wrong. Page not found." 95% of internet user has probably seen pages like these.
I think it's important that web developers consider paying less attention to building clever 404 pages and start eliminating broken links.
Web developers these days build clever 404 pages and started eliminating broken links. Therefore, it is very important to look for broken links in your site and fix those links before your readers are affected by them.
I've developed an automated script that will find broken links from the website.
The script is written in Python 3, and it recursively follows links on any given site and checks each one for 404 errors. Once the script finished searching the entire site, it will open an HTML file in your browser and display all the broken links. Based on the output of the HTML file, you can ask your developer/yourself to fix the issue.
What is BeautifulSoup?
First of all, let us understand what Beautiful Soup is: It is a library written in Python. It is used to extracts data out of HTML and XML files. Beautiful Soup works well if a company or website owner wants to get data quickly and saves programmers a lot of time.
Prerequisites
Make sure you have python installed.
Follow Python download link to get python installed in your system.
Also, set up a virtual environment using python3 for the app. To set up a virtual environment, you may run the below command.
$ python3 -m venv env
After creating a virtual environment, we need to activate the environment.
source env/bin/activate
The Script
As Python Beautiful Soup is an external module, to start working on it, we need to install it.
$ pip install bs4
$ pip install requests
Now, let us create a file called url-checker.py.
- Let us first import the required modules
import requests
import sys
from bs4 import BeautifulSoup
from urllib.parse import urlparse
from urllib.parse import urljoin
- Define our baseURL and FilePath where we want to save the html file
BASE_URL = sys.argv[1] if len(sys.argv) > 1 else "https://pratapsharma.io"
FILE_PATH = "/Users/pratap/personal/utils/"
- Now let us save the searched links and broken links in a list of their own.
searched_links = []
broken_links = []
- A function that will return a list of urls from an HTML file.
def getLinksFromHTML(html):
def getLink(el):
return el["href"]
return list(map(getLink, BeautifulSoup(html, features="html.parser").select("a[href]")))
- Finally, let us write a function which will run recursively.
def find_broken_links(domainToSearch, URL, parentURL):
is_searchable = (not (URL in searched_links)) and (not URL.startswith("mailto:")) and (not ("javascript:" in URL)) and (not URL.endswith((".png", ".jpg", ".jpeg")))
if is_searchable:
try:
resetObj = requests.get(URL)
searched_links.append(URL)
if(resetObj.status_code == 404):
broken_links.append({
"url": URL,
"parent_url": parentURL or 'Home',
'message': resetObj.reason
})
else:
if urlparse(URL).netloc == domainToSearch:
for link in getLinksFromHTML(resetObj.text):
find_broken_links(
domainToSearch, urljoin(URL, link), URL)
except Exception as e:
print("ERROR: " + str(e))
searched_links.append(domainToSearch)
- Once the function is defined its time to call the function.
find_broken_links(urlparse(BASE_URL).netloc, BASE_URL, "")
The script makes many internal HTTP requests. So be aware of time taken the Internet usage rate.
- Now let us create a HTML file and form the data using the
broken_linkslists.
with open('broken-links.html', 'w') as myFile:
myFile.write('<html>')
myFile.write(f'''
<head>
<style>
table {{
font-family: arial, sans-serif;
border-collapse: collapse;
width: 100%;
}}
td, th {{
border: 1px solid #dddddd;
text-align: left;
padding: 8px;
}}
tr:nth-child(even) {{
background-color: #dddddd;
}}
h2 {{
text-align: center;
}}
</style>
</head>
''')
myFile.write('<body>')
myFile.write(f'<h2>Broken links for site: {BASE_URL}</h2>')
myFile.write('<table>')
myFile.write('<tbody>')
myFile.write(
'<tr><th>SN</th><th>URL</th><th>Parent URL</th><th>Message</th></tr>')
for index, link in enumerate(broken_links):
myFile.write(
'<tr><td>{0}</td><td> <a href="{1}" style="color:red;" target="_blank">{1}</a></td><td> <a href="{2}" target="_blank">{2}</a></td><td>{3}</td></tr>'.format(index+1, link['url'], link['parent_url'], link['message']))
myFile.write('</tbody>')
myFile.write('</table>')
myFile.write('</body>')
myFile.write('</html>')
- Upon completition of the script we want to open the html file in the browser. To do so add the following lines in the code.
browser = webbrowser.get('chrome')
browser.open_new(f'file://{FILE_PATH}broken-links.html')
The script should open the HTML file in the browser directly.
It would look something like this
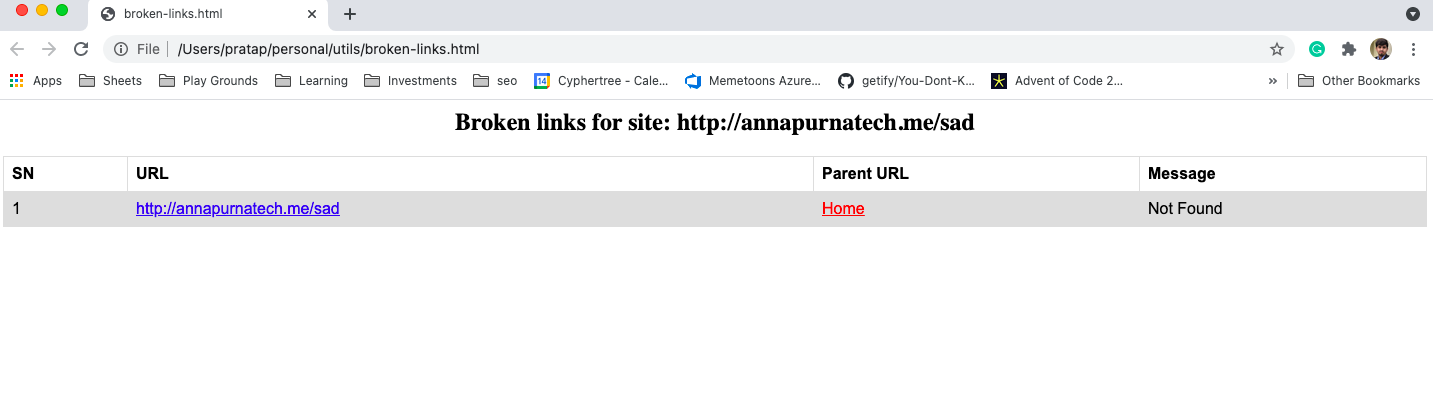
Adding all together
The content of the file at the end should look like this.
import requests
import sys
from bs4 import BeautifulSoup
from urllib.parse import urlparse
from urllib.parse import urljoin
import webbrowser
searched_links = []
broken_links = []
BASE_URL = sys.argv[1] if len(sys.argv) > 1 else "https://pratapsharma.io"
FILE_PATH = "/Users/pratap/personal/utils/"
print(
f'Running script for {BASE_URL} and saving the file to: {FILE_PATH}broken-links.html')
def getLinksFromHTML(html):
def getLink(el):
return el["href"]
return list(map(getLink, BeautifulSoup(html, features="html.parser").select("a[href]")))
def find_broken_links(domainToSearch, URL, parentURL):
is_searchable = (not (URL in searched_links)) and (not URL.startswith("mailto:")) and (not ("javascript:" in URL)) and (
not URL.endswith(".png")) and (not URL.endswith(".jpg")) and (not URL.endswith(".jpeg"))
if is_searchable:
try:
resetObj = requests.get(URL)
searched_links.append(URL)
if(resetObj.status_code == 404):
broken_links.append({
"url": URL,
"parent_url": parentURL or 'Home',
'message': resetObj.reason
})
else:
if urlparse(URL).netloc == domainToSearch:
for link in getLinksFromHTML(resetObj.text):
find_broken_links(
domainToSearch, urljoin(URL, link), URL)
except Exception as e:
print("ERROR: " + str(e))
searched_links.append(domainToSearch)
find_broken_links(urlparse(BASE_URL).netloc, BASE_URL, "")
# Converting above errors to html file
with open('broken-links.html', 'w') as myFile:
myFile.write('<html>')
myFile.write(f'''
<head>
<style>
table {{
font-family: arial, sans-serif;
border-collapse: collapse;
width: 100%;
}}
td, th {{
border: 1px solid #dddddd;
text-align: left;
padding: 8px;
}}
tr:nth-child(even) {{
background-color: #dddddd;
}}
h2 {{
text-align: center;
}}
</style>
</head>
''')
myFile.write('<body>')
myFile.write(f'<h2>Broken links for site: {BASE_URL}</h2>')
myFile.write('<table>')
myFile.write('<tbody>')
myFile.write(
'<tr><th>SN</th><th>URL</th><th>Parent URL</th><th>Message</th></tr>')
for index, link in enumerate(broken_links):
myFile.write(
'<td>{0}</td><td> <a href="{1}" style="color:red;" target="_blank">{1}</a></td><td> <a href="{2}" target="_blank">{2}</a></td><td>{3}</td>'.format(index+1, link['url'], link['parent_url'], link['message']))
myFile.write('</tbody>')
myFile.write('</table>')
myFile.write('</body>')
myFile.write('</html>')
# Selecting chrome as a browser and opening th html file in the browser
browser = webbrowser.get('chrome')
browser.open_new(f'file://{FILE_PATH}broken-links.html')
Usage
Run-on command line with a website of your choice.
$ python url-checker.py https://your_site.com/
Conclusion
I hope you found the article helpful, as it certainly helped me find a few broken links on my site. Our small web crawler is done. I hope this article was good for you.
💌 If you'd like to receive more tutorials in your inbox, you can sign up for the newsletter here.
Please don't hesitate to drop a comment here if I miss anything. Also, let me know if I can make the post better.
Discussions